LangChain Deep Agents in Plain English: What an "Agent Harness" Actually Is.
At LangChain's San Francisco agent conference, the most impressive thing was not a benchmark — it was the language. LangChain takes the messy engineering behind a production AI agent and names it in words anyone can follow: harness, sandbox, memory, skills, human-in-the-loop. Here is the whole deep agents picture translated into plain English — and why making the complex simple is the actual product. Part 3 of our San Francisco field notes.
We spent May in San Francisco for the agent launch circuit — Google I/O, the Notion developer platform, and the LangChain conference. We have already written up Google's new agent stack and the Notion career agent we shipped. This one is about LangChain — and what struck us was not a new model or a benchmark. It was the language.
LangChain has quietly become very good at something the rest of the industry is bad at: taking the genuinely complicated machinery behind a production AI agent and describing it in words a non-engineer can follow. Their deep agents session was a master class in it. So this piece does the same thing — it walks through the entire deep agents picture in plain English, one slide at a time.

What an "agent harness" actually is
Start with the word everything else hangs on: harness. An AI model on its own is just a text predictor. It cannot save a file, run code, remember yesterday, or ask you for approval. The harness is everything you build around the model to turn it into something that can do real work — the memory, the tools, the file storage, the safety checks, and the loop that keeps it going until the job is done.
A useful picture: the model is an engine. An engine bolted to nothing does not take you anywhere. The harness is the chassis, the fuel line, the steering, and the brakes. LangChain's deepagents is, in their words, a "batteries-included" harness — the whole car, assembled, instead of a box of parts.
Anatomy: the two halves of a harness
The first slide breaks the harness into two halves, and that split is the whole mental model.
The execution environment is where the agent gets to act. A code interpreter lets it run code. A sandbox is a safe, walled-off computer where that code runs without touching anything important. A filesystem gives it a place to read and write files — its workbench.
Context management is how the agent handles memory, because a model can only hold so much in its head at once. Skills are reusable instruction sheets it loads only when needed. Memory is what it carries between sessions. Summarization compresses long histories so they still fit. Context offloading parks big results in files instead of clogging the model's attention. Prompt caching reuses repeated context so things run faster and cheaper.
None of that is new engineering. What is new is that it is named, sorted, and explained on a single slide. That is the skill.

Middleware: where you insert your own rules
The second slide answers the obvious enterprise question — how do I make this follow my rules? The answer is middleware: checkpoints in the agent's loop where you can step in.
Read the flow plainly. A request comes in, then the agent moves through stages — before the agent starts, before it calls the model, around each model call and each tool call, after the model responds, after the agent finishes — and finally returns a result. At every one of those stages you can attach your own logic: business rules, policy enforcement, fault tolerance, limits on which tools are allowed to fire. (LangChain detailed this six-hook system in their anatomy of a harness writeup.)
In plain terms: the agent runs on rails, and middleware is where you decide what happens at each stop.

Human-in-the-loop, built in
The third slide is the one that matters most for regulated industries. A real agent doing real work has to be able to stop and ask a person before it does something sensitive — move money, send the email, delete the records.
Deep agents treats this as first class. The agent can wait for human input indefinitely, a person can approve, edit, or reject the proposed action, and — the important part — the pause is checkpointed for durability. That means the agent can be interrupted for an hour or a day, survive a server restart, and pick up exactly where it left off. (LangChain's docs cover the mechanics.)
This is the same principle we design every client system around: the machine finds and proposes; the human approves what matters.

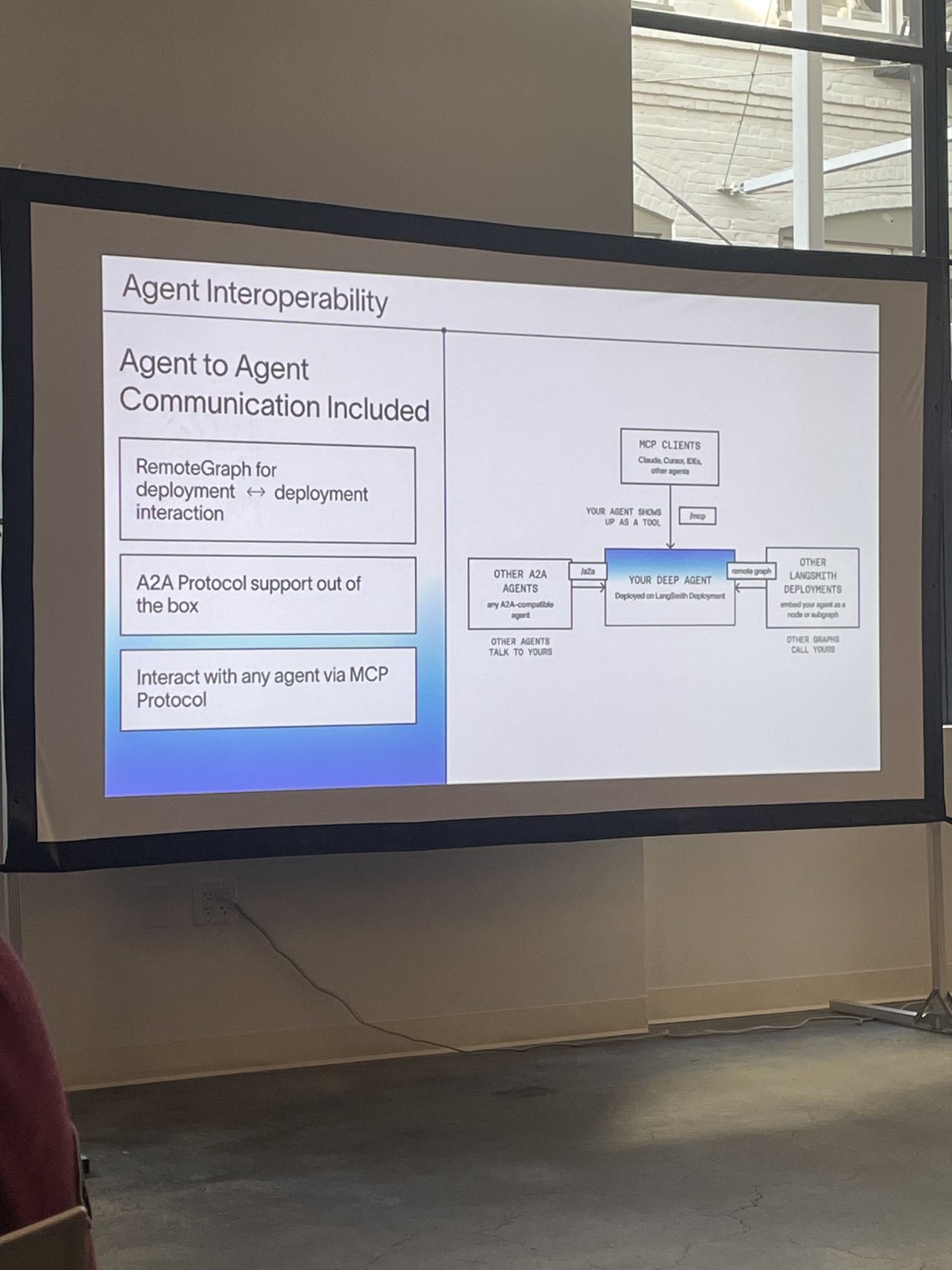
Agents that talk to other agents
The last slide is about the near future: agents do not work alone. Deep agents ships with three ways for your agent to connect to the wider world. MCP — the Model Context Protocol — lets it plug into tools and data. A2A — agent-to-agent — lets it talk to other agents, no matter who built them. RemoteGraph lets one agent call another that is deployed somewhere else as if it were sitting in the same room.
Deploy the whole thing on LangSmith and you inherit the production plumbing — versioning, instant rollbacks, fault tolerance — instead of building it yourself.
What we took from it
The deep agents stack is genuinely good engineering. But the thing we are carrying into client rooms is the communication, not the code. LangChain took a subject that usually arrives as intimidating jargon and made it legible — harness, sandbox, memory, skills, approval. A Fortune 500 executive can follow that slide without a computer science degree, and that is exactly the point at which they can make a decision about it.
That is the standard we hold our own work to. Most enterprise AI stalls not because the technology is too hard, but because no one translated it. The studios and vendors who win the next few years are the ones who break highly complex, highly logical problems down into simple words — and then ship the system underneath.
This is Part 3 of our San Francisco field notes — see Part 1 on Google I/O and Part 2 on the DeepMind after-hours. If your team is trying to separate what is real from what is noise in the agent space — and turn it into something your leadership can actually act on — that is what Enso Labs is built to do. Get in touch.
Frequently Asked Questions
What is a LangChain deep agent?
A deep agent is LangChain's "batteries-included" agent harness — an open-source Python library (pip install deepagents) built on LangGraph that bundles the parts a production AI agent needs: a code interpreter and sandbox, a virtual filesystem, context management (memory, skills, summarization, prompt caching), human-in-the-loop approvals, and agent-to-agent connectivity. It turns a raw language model into a system that can actually carry out multi-step work.
What is an agent harness?
An agent harness is everything built around a language model to make it useful: the loop that keeps it working, the tools it can call, its memory and file storage, context management, error handling, and human-approval checkpoints. The model is the engine; the harness is the rest of the car. LangChain's deep agents is one such harness.
How does human-in-the-loop work in LangChain deep agents?
Deep agents can pause mid-run and wait for a person to approve, edit, or reject a sensitive action, for as long as needed. Because the pause is checkpointed, the agent can survive restarts and resume exactly where it stopped — which makes it safe to put real, consequential actions behind a human approval step.
Want to scope an engagement around this?